Warning: Frequently pulling down a schedule of observations for multiple days can be expensive and prohibitively slow on remote connections - so we recommend utilizing the last_scheduled endpoint to avoid unnecessary bandwidth usage.
Telescope Control System Integration
For users who wish to adopt the Observatory Control System to manage submitting requests, scheduling and updating observations, the workflow is documented here.
For this document, we assume that an observatory has a Telescope Control System (TCS) which is capable of:
- Retrieving a schedule of observations from an instance of the OCS Observation Portal
- Executing each configuration specified in an observation’s request
- Reporting the status of each configuration to the OCS Observation Portal during and after the execution of the configuration
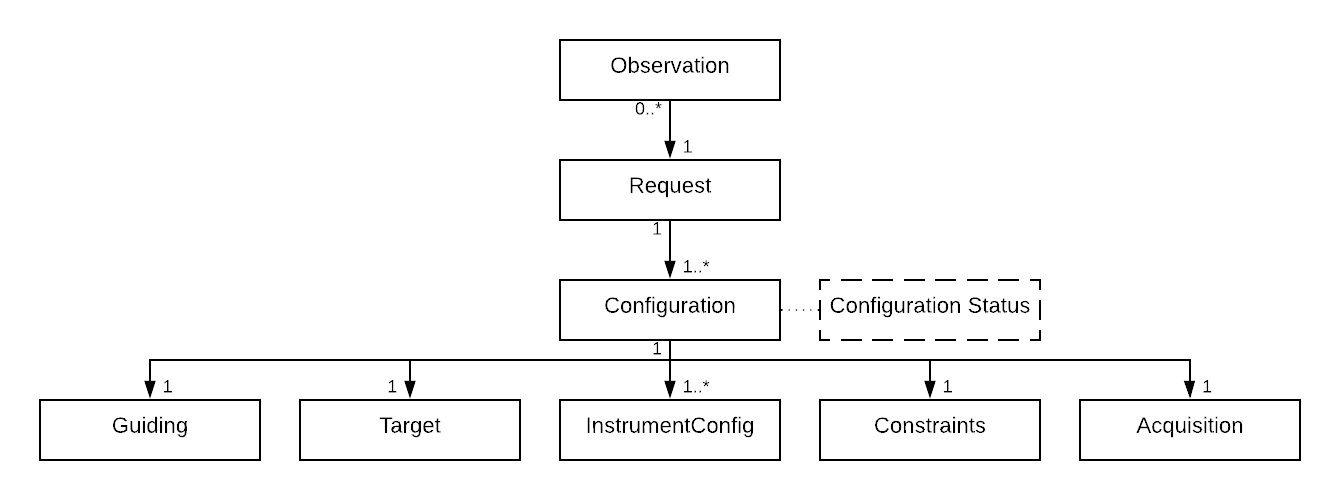
An observation is a scheduled request, or a request plus information about status, where the observation is scheduled, and when. The hierarchy of an Observation is shown below, but it is very similar to that of the Request except with a few additional pieces of information tacked on.
The TCS will need to execute each configuration from a request, updating the observation portal as the configuration progresses. A typical observation will look like this:
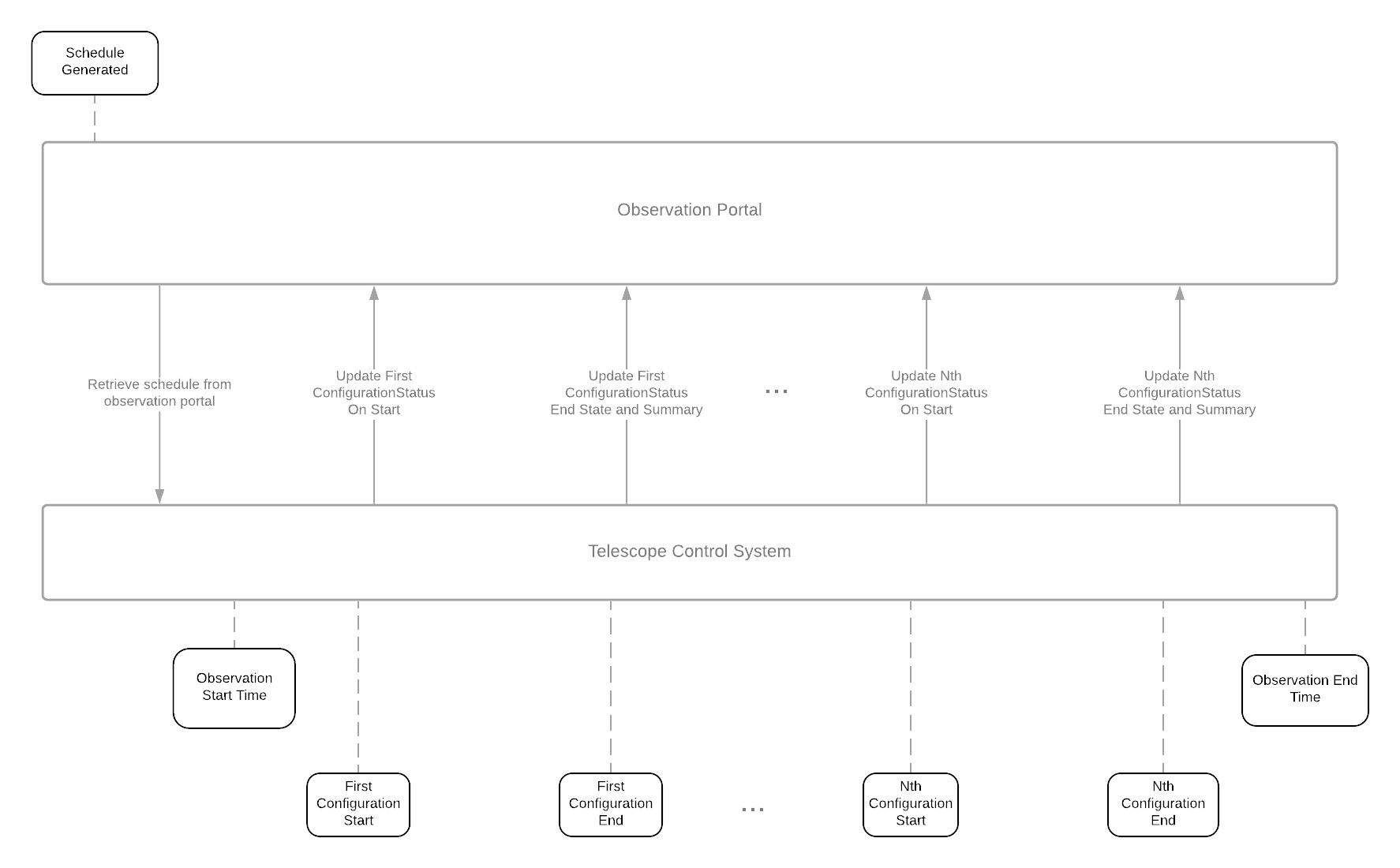
Within each configuration within the observation, there are details about its configuration status. The TCS can update this status at any time during the course of the execution of the configuration using the configuration_status id.
We recommend updating the status of a given configuration:
- At the beginning of execution of a configuration
- At the end of execution of a configuration
Retrieving a Schedule
Knowing When to Pull Down a Schedule
A TCS can determine when to pull down a new schedule by utilizing the /api/last_scheduled endpoint, which returns the time that the last schedule was generated for a given site (provided in the filter parameters).
GET /api/last_scheduled/?site=<site-code>
By storing the last time a schedule was retrieved and frequently polling (e.g. once every minute or less) this endpoint, the TCS can determine when it’s time to pull down a new schedule.
Pulling Down a Schedule
To retrieve the scheduled list of observations from the observation portal, the TCS will need to query the /api/schedule endpoint. In order to narrow down the results, this endpoint can be optionally filtered by the following fields:
- Site code
- Start/End time - Recommended window is from the current time to however far into the future your scheduler schedules its observations
- Enclosure code
- Telescope code
Note that this is a subset of the all available filterable fields - see the API documentation for a complete list.
GET /api/schedule/?site=<site-code>&start_after=<start-time>&end_before=<end-time>&enclosure=<enc-code>&telescope=<tel-code>
High-Level Workflow
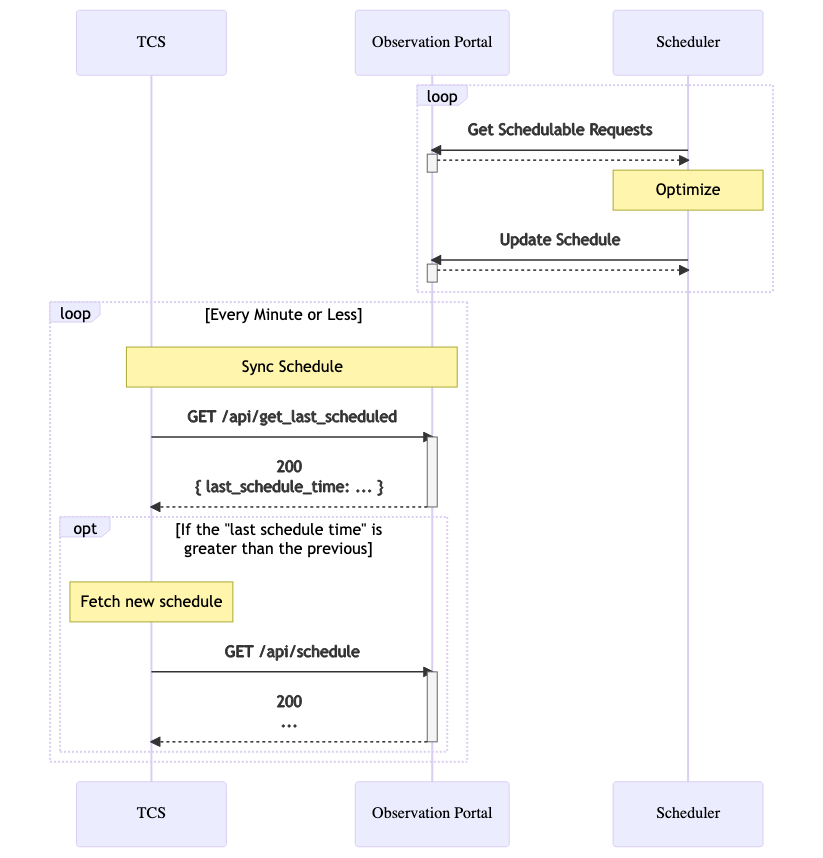
Below is a diagram that presents the high-level workflow of the TCS when pulling down a schedule.
Beginning of Configuration
By default, each configuration begins in PENDING state. As soon as the TCS begins a configuration, the TCS should update the ConfigurationStatus state to ATTEMPTED.
A HTTP PATCH request to /api/configurationstatus/<configurationstatus-id> with the following fields will update the state. Note that the configurationstatus-id can be found within the configuration_status field within each configuration of an observation.
{"state": "ATTEMPTED"}
Note: State changes in a configurationstatus from the TCS will trigger updates in the associated observation and request models, which will be reflected in the observation portal for users to view.
End of Configuration
When a configuration has terminated - either successfully or not - the configuration status must be updated, and a summary of events must be provided by the TCS.
Important: The “summary” portion of the ConfigurationStatus must be provided, as it is used for time accounting for each proposal.
In the case of a configuration that has successfully completed, a HTTP PATCH payload to the /api/configurationstatus/<configurationstatus-id> from the TCS will look like:
{"state": "COMPLETED",
"summary": {"start": "2022-01-01T00:00:00.000",
"end": "2022-01-01T00:05:10.000",
"state": "COMPLETED",
"reason": "",
"time_completed": "610.0",
"events": {}
}
}
- State: The final state of the configuration
- Possible final states as defined in the ConfigurationStatus model:
- NOT_ATTEMPTED
- COMPLETED
- FAILED
- Possible final states as defined in the ConfigurationStatus model:
- Summary - A final summary of the configuration
- Start: The actual start time of the configuration
- End: The actual end time of the configuration
- State: The final state of the configuration
- Reason (string): If the configuration failed, the reason why
- Events (JSON): A set of events reported by the TCS.
- Time completed: The exact amount of time spent exposing, in seconds
- Note: This is used to determine the percentage of actual exposure time taken versus what was requested, so that the “acceptability threshold” for a request is honored.
Data Product Archival
Once a TCS has generated data products from an observation, archival storage may be accomplished by using the OCS Science Archive, which provides utilities for storing file metadata and an HTTP REST API for querying archived data products. Ingestion of data products into a cloud filestore and file metadata into the OCS Science Archive is accomplished using the OCS Ingester Library.
For more information about integrating a TCS with the OCS Science Archive, see the Observatory Data Flow document.
Advanced Topics
Updating the End Time of an Configuration or Observation
In some cases it may be necessary to update the end time of an observation or configuration - for instance, if there are a wide range of overhead times (for slew, acquisition, etc.). If the scheduling system being used is running constantly, then it is beneficial to update the observation end times so that the scheduler knows when the observation is expected to end so that it can schedule the next observation directly following it. This can be accomplished by either updating the observation end time directly, or by reporting when the exposures of a configuration status started, which the observation portal will translate into an observation end time based on the associated overheads.
Updating Expected Observation End Time
To update the estimated end time of an observation, a simple HTTP PATCH request to the /api/observations/<id> will update the observation end time.
{"end": "2022-01-01T00:45:00.000"}
This will be visible to authorized clients of the observation portal, including a scheduler, so that the new end time can be taken into account when scheduling future observations.
Setting Exposure Start Time (exposures_start_at)
To set this, the TCS would send a HTTP PATCH request to the /api/configurationstatus/<id> with a JSON payload of the form:
{"exposures_start_at": "2022-01-01T00:30:00.000"}
Once the observation portal detects this update, it will update the end time of the observation automatically, using the overheads defined in the Configuration Database.
Setting Configuration(s) as NOT_ATTEMPTED
When executing an observation’s configurations, the terminal NOT_ATTEMPTED state may be set to indicate that the configuration wasn’t attempted by the TCS. This API feature is particularly useful when the TCS wants to indicate to the observation portal and/or scheduler that an observation should be re-scheduled because one or more of its configurations weren’t able to be attempted. This is in contrast to the FAILED state, which indicates that an observatory issue caused the execution of the configuration to fail.
The portal treats observations with configuration states of NOT_ATTEMPTED as follows:
| Observation State | Final Action by OCS |
|---|---|
| One or more configurations marked as NOT_ATTEMPTED | 1. If any configurations still PENDING observation is PENDING 2. Else, if all configurations have reached terminal state, observation is FAILED and will be re-scheduled. |
| All configurations marked as NOT_ATTEMPTED | Observation is marked as NOT_ATTEMPTED and will be re-scheduled. |
Rescheduling an Observation Started Late or Unable to Complete In Time
One important use-case for the NOT_ATTEMPTED state is when the TCS is able to determine that a scheduled observation has been started late (excessive slew time, acquisition time, etc.) and will not be able to be completed before the observation’s window expires. If this is determined early during the execution of an observation, then the TCS can mark all configurations as NOT_ATTEMPTED, the Observation Portal will then mark the observation as NOT_ATTEMPTED, and a scheduler can immediately re-schedule the observation.
In practice, if a TCS detects that no configurations have started within a certain amount of time (e.g. 10 minutes), it may decide to mark all configurations as NOT_ATTEMPTED and abort execution of the observation. This prevents the TCS from starting the observation late when there is no feasible way it can complete it in time.