Components
The Observatory Control System (OCS) is composed of several python libraries, applications, and Django web applications that work together to provide a complete upper stack solution to manage an observatory. The diagram below shows the major OCS components and how they are interconnected.
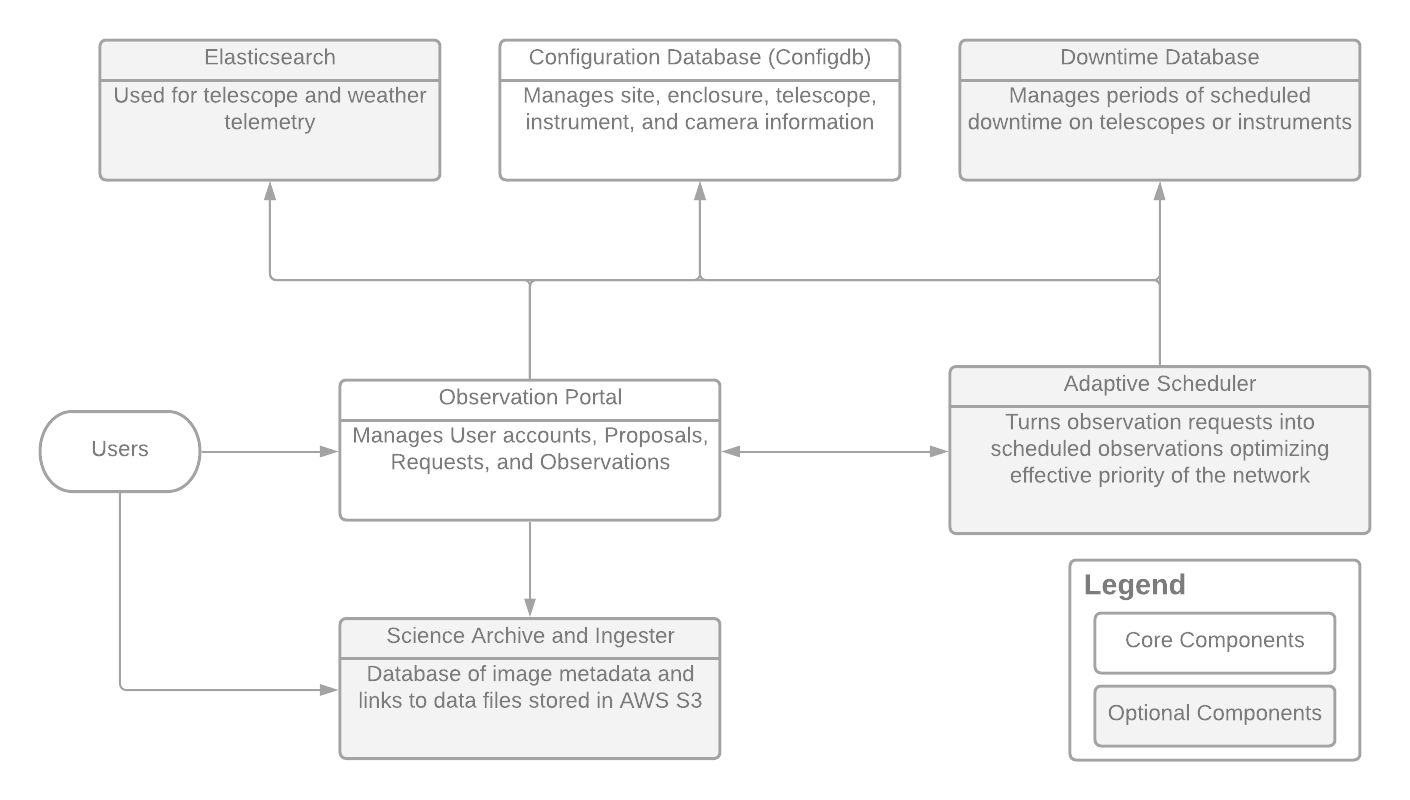
Core Components
The core of the OCS is the Observation Portal. It manages User accounts for all the other applications that need authentication, and it provides a database and API for submitting, updating, and viewing proposals, observation requests, and scheduled observations.
The Configuration Database (Configdb) manages the state of the observatory, as viewed by the other upper stack applications. It provides hierarchical models of the observatory’s structure, from the site/enclosure/telescope down to the modes and properties of cameras within an instrument. The purpose of this information is to allow automatic validation and auto-completion of observatory details when possible in the other applications.
These two applications represent the minimum viable portion of the OCS needed to manage users, proposals, and observation requests for an observatory.
Optional Components
The optional components are not required, but they expand the capabilities of an OCS software stack in various ways. If an observatory already has a custom solution for one of the components, such as scheduling or data archiving, then those can be integrated with the Observation Portal rather than using the OCS Adaptive Scheduler or Science Archive.
The Adaptive Scheduler provides a python application which interfaces with the other OCS databases to turn a set of input observation requests into a set of scheduled observations in the Observation Portal. While the scheduler is fully integrated into the OCS ecosystem, it is possible to use another scheduling method instead.
The Science Archive application and Ingester library provide the means to upload data products into Amazon Web Services (AWS) S3 buckets, and store their metadata in a database to allow for easy searching, filtering, and bulk downloading of the data products by users using the science archive API. AWS S3 provides a relatively inexpensive and scalable way for observatories to store data products redundantly and long-term, but if an observatory already has a solution for storing data products, they can continue to use that.
The Downtime Database is a simple database with a REST API and web frontend for creating and retrieving periods of planned downtime on a telescope or instrument. Using the downtime database isn’t strictly necessary, but it can increase scheduling efficiency at the observatory since observations can be scheduled exactly around the bounds of known periods of downtime.